摘要:以往,談及對合成語音的刻板印象,很多人會聯想到《星球大戰》中的C-3PO——那個有著近似人類外形金光閃閃的家伙,它是整個系列影片中毫無爭議的搞笑擔當,其動作僵硬而滑稽,說起話來喋喋不休,聲音中混雜著輕微的交流聲和金屬質感的回聲。直到今天,它那獨特的嗓音,仍然是很多科幻片中人工智能發聲的模板。
以往,談及對合成語音的刻板印象,很多人會聯想到《星球大戰》中的C-3PO——那個有著近似人類外形金光閃閃的家伙,它是整個系列影片中毫無爭議的搞笑擔當,其動作僵硬而滑稽,說起話來喋喋不休,聲音中混雜著輕微的交流聲和金屬質感的回聲。直到今天,它那獨特的嗓音,仍然是很多科幻片中人工智能發聲的模板。
第一部《星球大戰》公映于1977年,彼時,個人電腦才剛剛走出實驗室,人們對于人工智能的想象力仍受限于時代。去年,該系列推出了最后一部作品《星球大戰:天行者崛起》,C-3PO的聲音還是人們熟悉的老樣子。而現實中,智能語音技術飛速發展,取而代之的是聽感越來越趨于自然、逼真的“合成人聲”,讓越來越多的企業于實現了與客戶的多模態互動。
合成人聲的用途相當廣泛,我們熟知的便是手機中的語音助手,用戶可通過簡單的人機對話,獲知天氣、路況等實時信息,也可命令手機完成撥號、查詢等任務。這一類應用被稱作實時語音合成,它對基于云的計算力提出了很高的要求,除了需要對聲音的自然度不斷地進行優化外,實時合成對于語音合成引擎和平臺架構也都有著極高的要求,必須保障在極低的延遲下,提供準確、穩定、自然的聲音內容。另一類常見的應用是利用人工智能語音合成有聲內容,這類應用通常會在語音服務端進行非實時的批量合成,然后再將有聲內容文件提供給用戶。有聲內容合成的主要挑戰在于如何通過多種角色扮演和豐富情感表達,降低聽眾單向接收有聲內容的聽覺疲勞。
以往,有聲書需要由專業朗誦者來錄制,制作周期長達數月且成本高昂。如今,通過智能合成語音錄制有聲書,制作周期可縮短至幾小時,甚至是幾分鐘。即便在需要人工干預校對和聲音編輯的情況下,制作周期也可縮短至數周,節省了大量的人力、物力及時間成本,且得到的效果幾乎與真人朗誦別無二致。今年的“世界讀書日”,由周迅與公益組織紅丹丹聯合發起的為視障人士讀書活動,向我們展示了語音合成技術的新高度。在此之前,創建一個高質量的語音合成模型需要以大量真人原聲為樣本進行機器學習,樣本量通常會超過10小時或10000句。而這次公益活動的主辦方采用了由微軟最新開發的深度神經網絡語音合成定制系統,只采集了半小時大約500句的周迅原聲錄音,便通過深度定制的語音模型,惟妙惟肖地復原了周迅的聲音。
這里所說的“復原”不只是周迅頗具特色的聲線,也包括周迅在朗讀時的語氣、情緒、語調、抑揚頓挫等。可以想象,隨著這一技術的普及,有聲書行業也將隨之發生巨大的改變。微軟將在國際殘疾人日捐贈的100小時有聲書籍正昭示著這種改變的開始。
微軟深度神經網絡是基于Azure云的端到端語音合成系統,由前端、聲學模型和聲碼器三部分組成。前端主要解決基于語義理解的文本發音問題,比如“2020”在表示年份和數字時的讀法不一樣,這是上下文關聯問題;再比如“堡”字,用于地名時應讀作“鋪”,“解”用在姓氏上應讀作“謝”,這都是多音字問題;還有“一會兒”這類詞,不能讀成三個字,后兩個字應合并為兒化音,這是語言習慣問題。聲學模型負責為語音賦予韻律,比如語速、語調、停頓、重音和情緒變化等。最后一部分聲碼器負責還原語音的聲學特征,也就是一般所說的嗓音或聲線,如振幅、頻率、波長等。
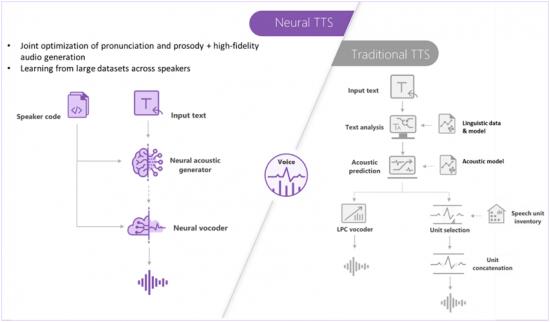
深度神經網絡模型是當前最先進的語音合成技術,但相應的主流產品在合成效率、效果,以及所需聲音樣本量上,卻存在很大差異。以樣本量為例,微軟的語音合成定制技術處于行業領先地位,一般情況下,只需要不超過2000句的內容,就可以做到非常逼真的還原。那么,在周迅的案例中,是如何做到只需500句甚至更少的聲音素材就達到類似效果呢?微軟還有一個“殺器”——通用模型。通用模型是在對海量語料庫進行大數據分析的基礎上,不斷訓練深度神經網絡去學習人類語言與發聲特征后得到的。目前微軟通用語料庫的容量已經超過3000小時,覆蓋了50多個語種,通過它提煉出來的通用模型已經熟練掌握了這50多種語言的幾乎全部發聲規律,甚至包括真人說話時換氣和咽口水的細節都可以模仿出來。當微軟需要基于像周迅這樣只有500句話甚至更少內容的語料庫做語音定制時,便可以在通用模型基礎上,通過遷移學習法來建立周迅聲音的擴展模型。
目前,微軟的語音合成定制系統只需要半小時左右的聲音樣本便可建立定制語音模型,與傳統TTS建模所需的至少10小時或10000句的聲音樣本量相比,是一個從量到質的飛躍。這一飛躍使得面向更多的企業甚至于普通消費者的個人聲音定制成為可能。

微軟之所以能在語音合成領域保持領先地位,主要得益于其20多年來在算法和定制模型上所積累的深厚功力。自從1991年微軟研究院成立以來,微軟一直將語音作為主要的研究領域,儲備、積累了大量的人工智能相關技術。2018年9月,微軟率先開始測試基于深度神經網絡的端到端語音合成系統,為人工智能語音技術的發展揭開了新的一頁。
前不久,微軟將其定制的通用中文發聲與市場上的主流產品進行了盲測對比,微軟的MOS得分(5分制)為4.35,居于領先地位,表明合成語音與真人聲音已經非常接近(真人的MOS得分為4.41)。
除了語音助手和有聲書籍錄制外,語音合成技術還廣泛應用于智能語音客服領域,這也是微軟目前在to B領域的主要發力點,比如很多航空公司、電商平臺、電信運營商等都在嘗試使用微軟的智能語音客服來緩解人工壓力。智能語音客服可以解決很多常見的標準化問題,減少客戶的等待時間,為客戶帶來更好的服務體驗。在應對突發事件方面,智能語音客服更有得天獨厚的優勢,很多突發事件都會造成客戶咨詢量在短時間內爆發式增長,在這種情況下,企業如果增設人工客服,一方面可能在時間上來不及,另一方面倉促上崗也可能導致服務質量的難以保證。
目前,微軟為企業定制智能語音客服大致需要300至2000句語料訓練,以滿足特定應用場景的需求;對于需要定制適用于多場景、富有多種情緒甚至涵蓋多語種的品牌聲音的企業而言,語料訓練則有更高要求。
上述兩種定制目前都會有人工參與測試和適當調校并向客戶提供靈活的接入方式,即通過API或SDK接入微軟的Azure公有云,實現端到端的實時合成。如果客戶有特殊需求,產品也可部署在私有云甚至離線設備中。未來,這兩種系統都將實現自動化定制。實際上,微軟已經邀請合作伙伴開始小范圍的自動化系統測試,可能在不久的將來正式發布此系列產品。
可以預期,伴隨著相關技術的發展,智能語音在個人及商業領域中的應用場景將更加豐富,不斷細分的合成語音服務也會給我們帶來更多的體驗和驚喜。同時,微軟提出了人工智能六項倫理道德準則:公平、可靠和安全、隱私和保證、包容、透明和責任。倡導負責任的人工智能。這些原則將為人工智能的發展保駕護航,予力全球每一人、每一組織,成就不凡!

直播鏈接:https://live.bilibili.com/h5/4306336
*本文圖片均來源于網絡



2025年4月9日,深圳開鴻數字產業發展有限公司(以下簡稱"深開鴻")在廣東省人工智能與機器人產業創...
 2025-04-09
2025-04-09中糧餐飲持續深耕“橫向多元化、縱向專業化”的高質量供應鏈發展體系初具雛形,在2025供應鏈生態共創大...
2025-04-09
2025年4月8至11日,以"創新科技,智領未來"為主題的第91屆中國國際醫療器械博覽會在國家會展中...
2025-04-09

在人工智能技術重塑全球產業格局的浪潮中,醫療健康領域正迎來一場深刻的變革。
2025-04-09

投資家網(www.51baobao.cn)是國內領先的資本與產業創新綜合服務平臺。為活躍于中國市場的VC/PE、上市公司、創業企業、地方政府等提供專業的第三方信息服務,包括行業媒體、智庫服務、會議服務及生態服務。長按右側二維碼添加"投資哥"可與小編深入交流,并可加入微信群參與官方活動,趕快行動吧。








投資家網(http://www.51baobao.cn/)隸屬于北京微金科技有限公司,是國內知名的資本與產業創新綜合服務平臺。平臺聚集數百萬優秀創業者、資深PE/VC、投資銀行家、上市公司及實業高管、專家學者等,致力于構建起資本、產業與政府之間的橋梁與生態服務體系。
郵箱:bp@wefinances.com
微信:yangqin6060
微信:15201337588






Copyright ? 投資家網 | 京ICP備16014291號-1 | 京公安備11010502031933號網站地圖![]()

微博

微信公眾平臺