摘要:2023年10月11日,第九屆HAOMOAIDAY盛大開幕。本次HAOMOAIDAY以“BETTERAI,BETTERHAOMO”為主題,內容豐富,既有業內專家的精彩講座和尖端技術的展覽,同時也設有多個活潑有趣的活動和互動環節,使參與者深刻體驗到了自動駕駛技術的吸引力和可能性。
2023年10月11日,第九屆HAOMO AI DAY盛大開幕。本次HAOMO AI DAY以“BETTER AI,BETTER HAOMO”為主題,內容豐富,既有業內專家的精彩講座和尖端技術的展覽,同時也設有多個活潑有趣的活動和互動環節,使參與者深刻體驗到了自動駕駛技術的吸引力和可能性。
歷屆HAOMO AI DAY的核心主題都是聚焦最硬核的自動駕駛AI技術。此次,毫末智行CEO顧維灝帶來了主題為《自動駕駛3.0時代:大模型將重塑汽車智能化的技術路線》的演講,分享了毫末對于自動駕駛3.0時代AI開發模式的思考以及自動駕駛生成式大模型毫末DriveGPT大模型的最新進展和實踐。

(毫末智行CEO顧維灝)
顧維灝認為,自動駕駛3.0時代與2.0時代相比,其開發模式和技術框架都將發生顛覆性的變革。在自動駕駛2.0時代,以小數據、小模型為特征,以Case任務驅動為開發模式。而自動駕駛3.0時代,以大數據、大模型為特征,以數據驅動為開發模式。

(毫末提出的自動駕駛3.0時代的技術架構演進趨勢)
相比2.0時代主要采用傳統模塊化框架,3.0時代的技術框架會發生顛覆性變化。首先,自動駕駛會在云端實現感知大模型和認知大模型的能力突破,并將車端各類小模型逐步統一為感知模型和認知模型,同時將控制模塊也AI模型化。隨后,車端智駕系統的演進路線也是一方面會逐步全鏈路模型化,另一方面是逐步大模型化,即小模型逐漸統一到大模型內。然后,云端大模型也可以通過剪枝、蒸餾等方式逐步提升車端的感知能力,甚至在通訊環境比較好的地方,大模型甚至可以通過車云協同的方式實現遠程控車。最后,在未來車端、云端都是端到端的自動駕駛大模型。
顧維灝還詳細介紹了毫末DriveGPT大模型在推出200天后的整體進展。首先是DriveGPT訓練數據規模提升。截至2023年10月DriveGPT雪湖·海若共計篩選出超過100億幀互聯網圖片數據集和480萬段包含人駕行為的自動駕駛4D Clips數據。其次是通用感知能力提升,DriveGPT通過引入多模態大模型,實現文、圖、視頻多模態信息的整合,獲得識別萬物的能力;同時,通過與NeRF技術整合,DriveGPT實現更強的4D空間重建能力,獲得對三維空間和時序的全面建模能力;最后是通用認知能力提升,借助大語言模型,DriveGPT將世界知識引入到駕駛策略中。
顧維灝認為,未來的自動駕駛系統一定是跟人類駕駛員一樣,不但具備對三維空間的精確感知測量能力,而且能夠像人類一樣理解萬物之間的聯系、事件發生的邏輯和背后的常識,并且能基于這些人類社會的經驗來做出更好的駕駛策略,真正實現完全無人駕駛。
毫末DriveGPT是如何具備識別萬物的他通用感知能力,以及擁有世界知識的通用認知能力?顧維灝也給出了詳盡解釋。

(毫末DriveGPT升級:大模型讓自動駕駛擁有世界知識)
在感知階段,DriveGPT首先通過構建視覺感知大模型來實現對真實物理世界的學習,將真實世界建模到三維空間,再加上時序形成4D向量空間;然后,在構建對真實物理世界的4D感知基礎上,毫末進一步引入開源的視覺文本多模態大模型,構建更為通用的語義感知大模型,實現文、圖、視頻多模態信息的整合,從而完成4D向量空間到語義空間的對齊,實現跟人類一樣的“識別萬物”的能力。
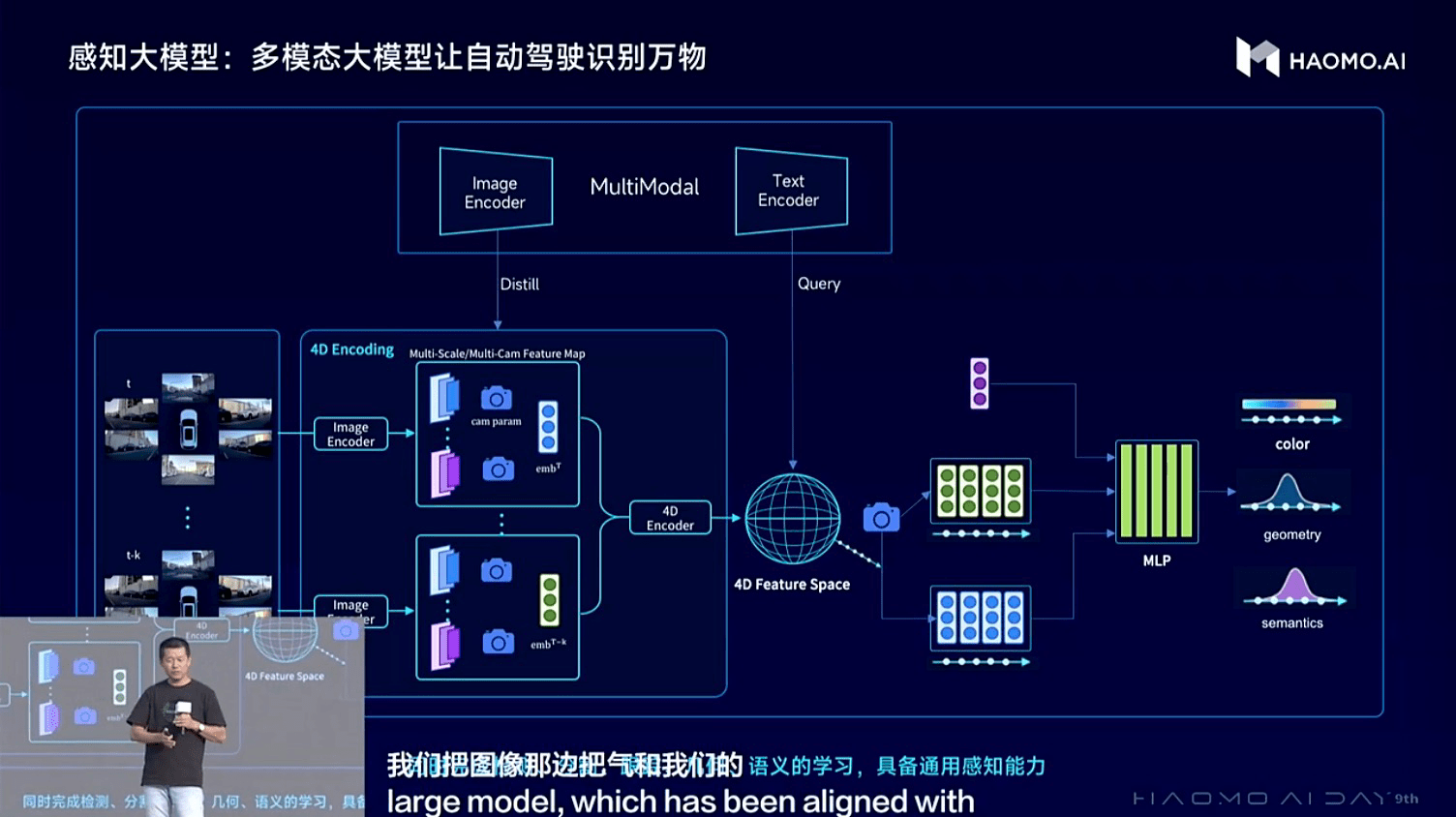
(毫末DriveGPT通用感知大模型:讓自動駕駛認識萬物)
毫末通用感知能力的進化升級包含兩個方面。首先是視覺大模型的CV Backbone的持續進化,當前基于大規模數據的自監督學習訓練范式,采用Transformer大模型架構,實現視頻生成的方式來進行訓練,構建包含三維的幾何結構、圖片紋理、時序信息等信息的4D表征空間,實現對全面的物理世界的感知和預測。其次是構建起更基礎的通用語義感知大模型,在視覺大模型基礎上引入視覺文本多模態模型來提升感知效果,視覺文本多模態模型可以對齊自然語言信息和圖片的視覺信息,在自動駕駛場景中就可以對齊視覺和語言的特征空間,從而具備識別萬物的能力,也由此可以更好完成目標檢測、目標跟蹤、深度預測等各類任務。
在認知階段,基于通用語義感知大模型提供的“萬物識別”能力,DriveGPT通過構建駕駛語言(Drive Language)來描述駕駛環境和駕駛意圖,再結合導航引導信息以及自車歷史動作,并借助外部大語言模型LLM的海量知識來輔助給出駕駛決策。
由于大語言模型已經學習到并壓縮了人類社會的全部知識,因而也就包含了駕駛相關的知識。經過毫末對大語言模型的專門訓練和微調,從而讓大語言模型更好地適配自動駕駛任務,使得大語言模型能真正看懂駕駛環境、解釋駕駛行為,做出駕駛決策。認知大模型通過與大語言模型結合,使得自動駕駛認知決策獲得了人類社會的常識和推理能力,也就是獲得了世界知識,從而提升自動駕駛策略的可解釋性和泛化性。

(毫末DriveGPT應用的七大實踐)
在分享了最新DriveGPT大模型技術框架后,顧維灝隨后也給出了毫末基于DriveGPT大模型開發模式的七大應用實踐,包括駕駛場景理解、駕駛場景標注、駕駛場景生成、駕駛場景遷移、駕駛行為解釋、駕駛環境預測和車端模型開發。
其中,在駕駛行為解釋方面,毫末DriveGPT在原有結合場景庫及人工標注方式來對駕駛行為進行解釋的基礎上,升級為引入大語言模型來解釋駕駛環境,讓AI自己解釋自己的駕駛決策。接下來,毫末會持續通過構建自動駕駛描述數據,來對大語言模型進行微調,讓大語言模型能夠像駕校教練或者陪練一樣,對駕駛行為做出更詳細的解釋。

(駕駛行為解釋:透視AI的思考過程)
駕駛環境預測方面,毫末DriveGPT原來基于海量人駕數據預訓練和接管數據的反饋強化學習來完成未來BEV場景的預測生成,現在則是通過引入大語言模型,在使用駕駛行為數據的同時,讓大語言模型對當前的駕駛環境給出解釋和駕駛建議,然后再將駕駛解釋和駕駛建議作為prompt輸入到生成式大模型,來讓自動駕駛大模型獲得外部大語言模型內的人類知識,從而具備常識,才能理解人類社會的各種明規則、潛規則,才能跟老司機一樣,預測未來最有可能出現的駕駛場景,從而與各類障礙物進行更好地交互。

(駕駛環境預測:生成未來世界)
車端模型開發模式變革方面,毫末正在嘗試用蒸餾的方法,也就是用大模型輸出的偽標簽作為監督信號,讓車端小模型來學習云端大模型的預測結果,或者通過對齊Feature Map的方式,讓車端小模型直接學習并對齊云端的Feature Map,從而提升車端小模型的能力。基于蒸餾的方式,可以讓車端的感知效果提升五個百分點。
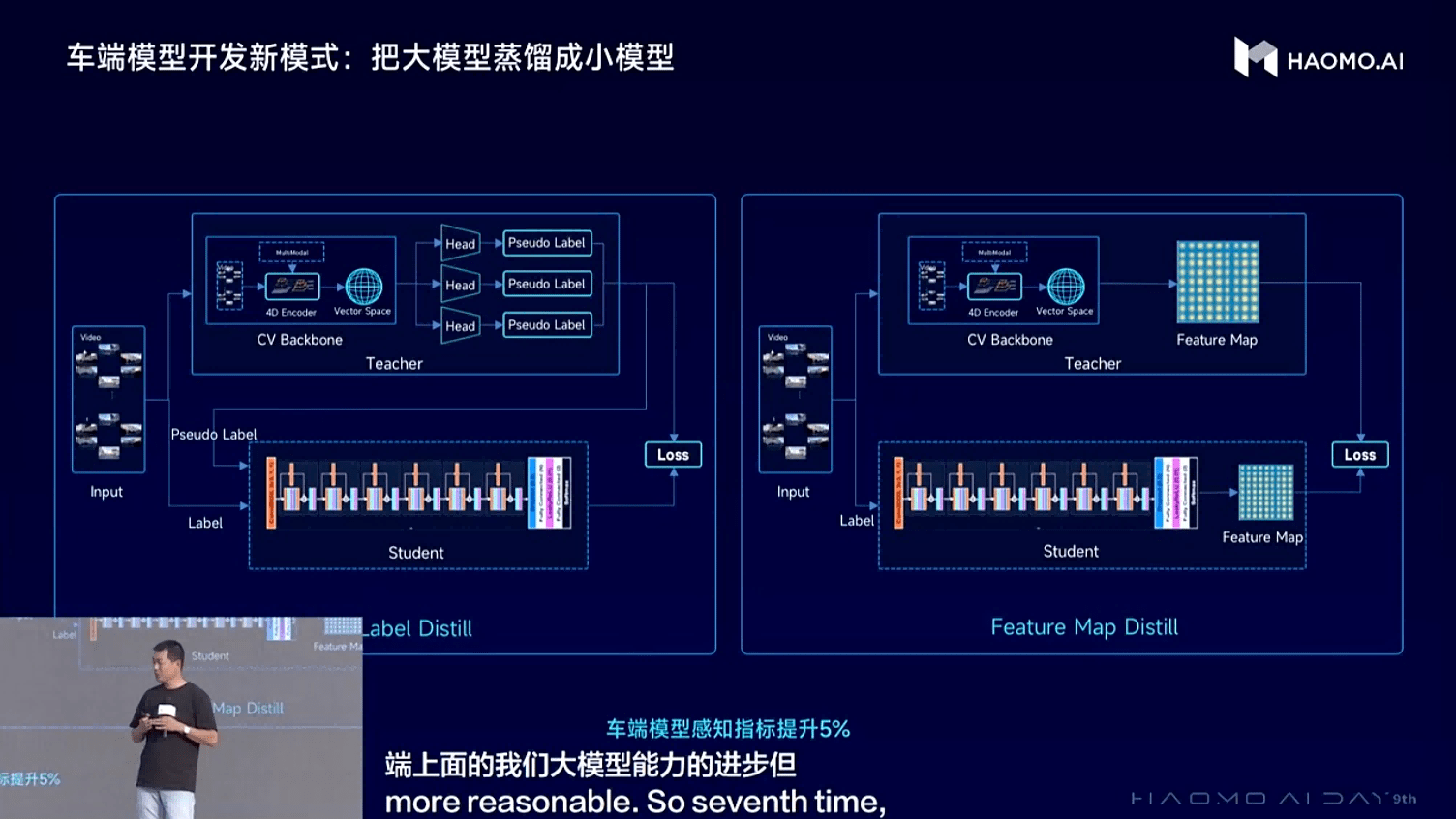
(車端模型開發新模式:把大模型蒸餾成小模型)
此外,毫末DriveGPT的駕駛場景理解可以對海量駕駛場景數據進行秒級特征搜索,從而實現更高效的數據篩選,為大模型挖掘海量高質量訓練數據;駕駛場景標注是采用了開集(Open-set)場景下的Zero-Shot自動標注,可實現對任意物體既快速又精準的標注,不僅可實現針對新品類的Zero-Shot快速標注,而且精度還非常高,預標注準召達到80%以上;駕駛場景生成,可以基于駕駛場景的文生圖模型,通過文字描述批量生成平時難以獲取的Hardcase數據,實現無中生有的可控生成;對于駕駛場景遷移,基于AIGC生成能力,可實現多目標場景生成,能將采集到的一個場景,遷移到該場景的不同時間、不同天氣、不同光照等各類新場景下,可同時獲取全天候駕駛數據,實現瞬息萬變的高效場景遷移。
現場,顧維灝還給出了DriveGPT賦能車端的三大測試成果:
第一個是毫末純視覺自動泊車測試成果。毫末利用視覺感知模型,使用魚眼相機可以識別墻、柱子、車輛等各類型的邊界輪廓,形成360度的全視野動態感知,可以做到在15米范圍內達到30cm的測量精度,2米內精度可以高于10cm。這樣的精度可實現用視覺取代USS,從而進一步降低整體智駕方案成本。

(毫末純視覺泊車)
第二個是毫末對交通場景全要素識別測試成果。DriveGPT基于通用感知的萬物識別的能力,從原有感知模型只能識別少數幾類障礙物和車道線,到現在可以識別各類交通標志、地面箭頭,甚至井蓋等交通場景的全要素數據。大量高質量的道路場景全要素標注數據,可以有效幫助毫末重感知的車端感知模型實現效果的提升,助力城市NOH的加速進城。
第三個是毫末城市NOH對小目標障礙物檢測的測試成果。毫末在當前城市NOH的測試中,可以在城市道路場景中,在時速最高70公里的50米距離外,就能檢測到大概高度為35cm的小目標障礙物,可以做到100%的成功繞障或剎停,這樣可以對道路上穿行的小動物等移動障礙物起到很好地檢測保護作用。
據顧維灝透露,DriveGPT的云端能力也對外開放,合作伙伴可以通過使用API、模型的專項優化、服務的私有化部署,與毫末合作。DriveGPT發布200天左右的時間里,累積480萬段Clips高質量測試。目前已有生態伙伴17家,助力生態伙伴提效90%。2023年DriveGPT成功入選“北京市通用人工智能產業創新伙伴計劃”成為首批模型伙伴觀察員及入選北京市首批人工智能10個行業大模型應用案例。此外,DriveGPT還助力毫末榮獲2023中國AI基礎大模型創新企業的稱號。
顧維灝也提到,毫末DriveGPT大模型的應用,在自動駕駛系統開發過程中帶來了巨大技術提升,使得毫末的自動駕駛系統開發徹底進入了全新模式,新開發模式和技術架構將大大加速汽車智能化的進化進程。
2025年4月17日,益盛藥業(002566.SZ)發布2024年財務報告,報告期內實現營業收入6....
 2025-04-18
2025-04-184月17日晚,深耕精密互連領域的創益通(300991.SZ)披露了2024年業績報告,公司業績表現良...
2025-04-18

4月17日,貝殼最新公告顯示,貝殼董事會主席、首席執行官及控股股東彭永東擬捐贈9,000,000股A...
2025-04-17

投資家網(www.51baobao.cn)是國內領先的資本與產業創新綜合服務平臺。為活躍于中國市場的VC/PE、上市公司、創業企業、地方政府等提供專業的第三方信息服務,包括行業媒體、智庫服務、會議服務及生態服務。長按右側二維碼添加"投資哥"可與小編深入交流,并可加入微信群參與官方活動,趕快行動吧。






賽那德完成超億元B輪系列融資,提升裝卸貨機器人實力
申科譜獲超億元“B+輪”融資,加速產業發展
陜西麥科奧特醫藥完成超億元D輪融資,浙商創投領投


投資家網(http://www.51baobao.cn/)隸屬于北京微金科技有限公司,是國內知名的資本與產業創新綜合服務平臺。平臺聚集數百萬優秀創業者、資深PE/VC、投資銀行家、上市公司及實業高管、專家學者等,致力于構建起資本、產業與政府之間的橋梁與生態服務體系。
郵箱:bp@wefinances.com
微信:yangqin6060
微信:15201337588






Copyright ? 投資家網 | 京ICP備16014291號-1 | 京公安備11010502031933號網站地圖![]()

微博

微信公眾平臺